[LeetCode October Challange] Day 20 - Clone Graph
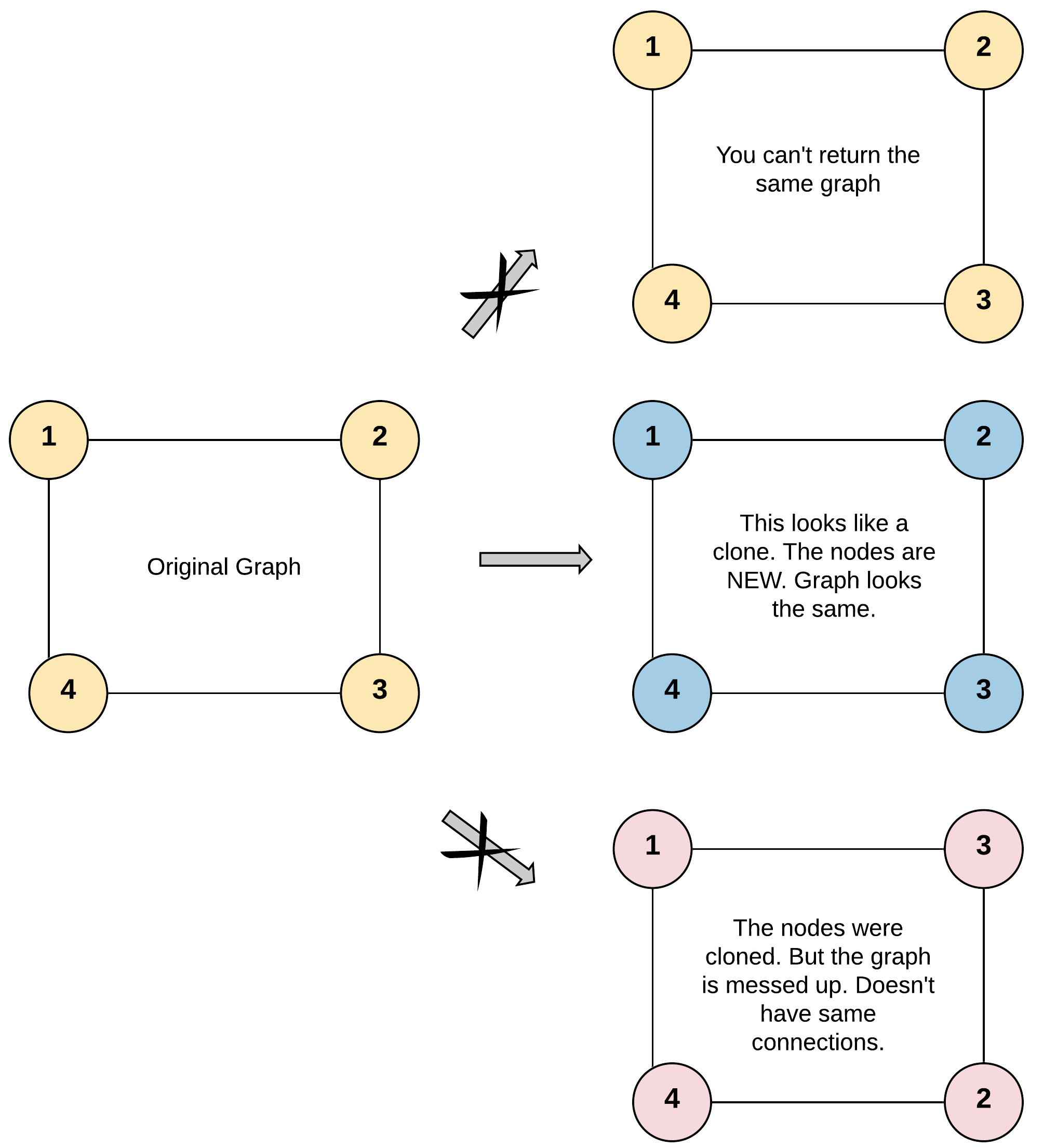
Given a reference of a node in a connected undirected graph.
Return a deep copy (clone) of the graph.
Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity sake, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val = 1, the second node with val = 2, and so on. The graph is represented in the test case using an adjacency list.
Adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
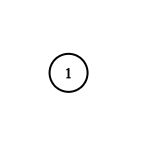
Input: adjList = [[]]
Output: [[]]
Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
Input: adjList = []
Output: []
Explanation: This an empty graph, it does not have any nodes.
Example 4:

Input: adjList = [[2],[1]]
Output: [[2],[1]]
Constraints:
- 1 <= Node.val <= 100
-
Node.val
is unique for each node.
- Number of Nodes will not exceed 100.
- There is no repeated edges and no self-loops in the graph.
- The Graph is connected and all nodes can be visited starting from the given node.
Solution
DFS
Time complexity : O(V+E)
Space complexity : O(V+E)
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
if (nullptr == node) return node;
if (0 < visited.count(node)) return visited[node];
Node* cur = new Node(node->val);
visited[node] = cur;
for (Node* neighbor: node->neighbors) {
cur->neighbors.push_back(cloneGraph(neighbor));
}
return cur;
}
private:
unordered_map<Node*, Node*> visited;
};
BFS
Time complexity : O(V+E)
Space complexity : O(V+E)
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
if (nullptr == node) return node;
queue<Node*> q;
q.push(node);
Node* root = new Node(node->val);
visited[node] = root;
while (!q.empty()) {
Node* cur = q.front(); q.pop();
for (Node* neighbor: cur->neighbors) {
if (0 == visited.count(neighbor)) {
visited[neighbor] = new Node(neighbor->val);
q.push(neighbor);
}
visited[cur]->neighbors.push_back(visited[neighbor]);
}
}
return root;
}
private:
unordered_map<Node*, Node*> visited;
};
不管是DFS還是BFS,都建一個hash table存放原node相對應的新node,藉以了解新舊對應關係。
DFS使用recursive的方式寫,應該很好理解。
但因recursive的方式,若考量到stack空間,可改用BFS,iterative的方式寫。
BFS,iterative,就是用一個queue來存放下一階段要處理的neighbors。
剩下的新增node、連線,做法都差不多。